Krishna Srikar Durbha
I am a fourth-year Ph.D. student at the Laboratory of Image and Video Engineering, The University of Texas at Austin, advised by Prof. Alan Bovik. I collaborate with the Meta Video Infrastructure Team on Video Engineering and Perceptual Quality Optimization.
My current research advances generative modeling for vision and Multimodal Large Language Models (MLLMs) — investigating few-step generation frameworks, MeanFlows, and visual grounding. Building on my prior work in representation learning and perceptual quality assessment (IQA/VQA), I design and train generative and multimodal models that are semantically faithful and perceptually high-fidelity.

Education
-
 Ph.D. in Electrical and Computer Engineering
Ph.D. in Electrical and Computer Engineering
2022 - Present
The University of Texas at Austin
Advisor: Dr. Alan C. Bovik -
Bachelor of Technology in Electrical Engineering
2018 - 2022
Indian Institute of Technology Hyderabad
Research Interests
- Generative Modeling
- Image and Video Representation Learning
- Perceptual Quality Assessment
- Multimodal Large Language Models
- Computer Vision
- Image and Video Processing
- Video Streaming Optimization
News
- 01/2026Passed my PhD Progress Review.
- 09/2025Completed my PhD candidate evaluation.
- 07/2025My paper Constructing Per-Shot Bitrate Ladders Using Visual Information Fidelity has been accepted to IEEE Transactions on Image Processing.
- 07/2025My paper Perceptual Classifiers: Detecting Generative Images using Perceptual Features has been accepted to the VQualA Workshop at ICCV 2025.
- 05/2025Excited to join the MPI team at Samsung Research America.
- 05/2024Excited to join the Wireless team at Skydio.
- 02/2024My paper Bitrate Ladder Construction using Visual Information Fidelity was accepted at PCS 2024.
- 12/2023Presented my work on Bitrate Ladder Construction at Video Quality Experts Group (VQEG) Meeting.
Ongoing Research
Active-
MeanFlows for Few-Step Generation
Investigating MeanFlows as a framework for efficient few-step generation, training generative models that synthesize high-fidelity samples in a handful of sampling steps.
-
Visual Grounding of Multimodal LLMs
Studying visual grounding techniques for Multimodal Large Language Models, improving how they localize and reason over visual content to produce semantically faithful, perceptually high-fidelity outputs.
Preprints & Under Review
Submitted
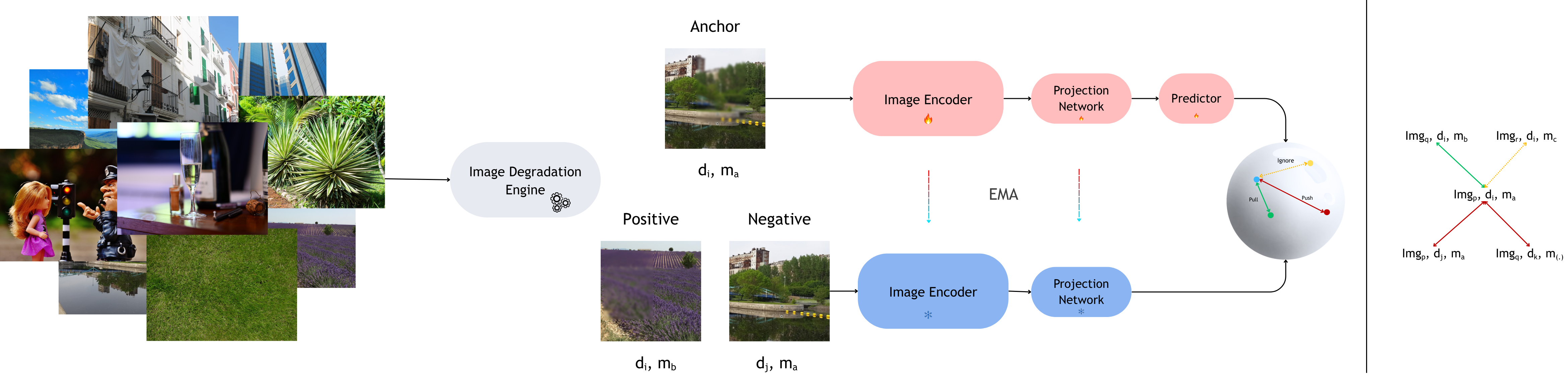
Spatially Localized Image Degradation Embeddings for Image Quality Assessment
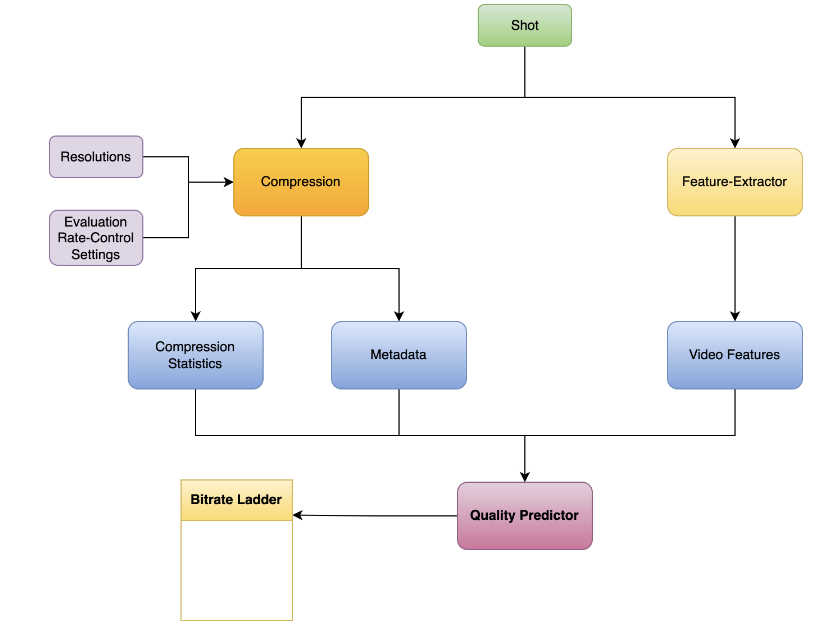
Leveraging Compression to Construct Transferable Bitrate Ladders
Published Papers
Peer-Reviewed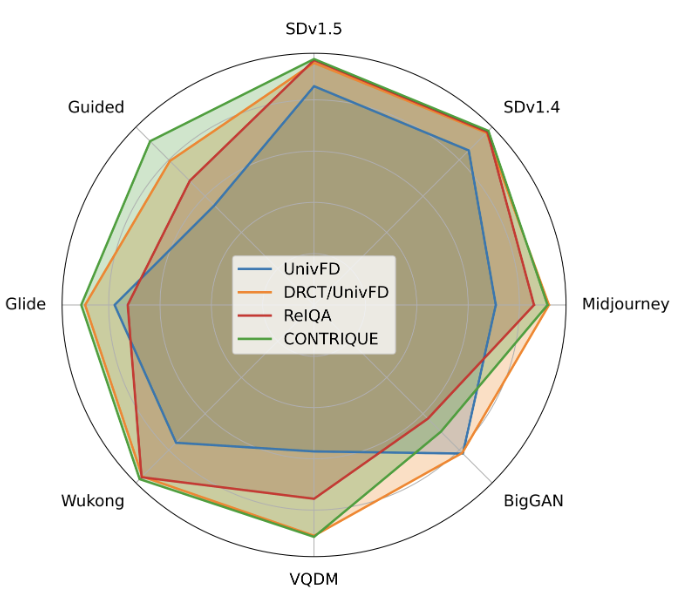
Perceptual Classifiers: Detecting Generative Images using Perceptual Features
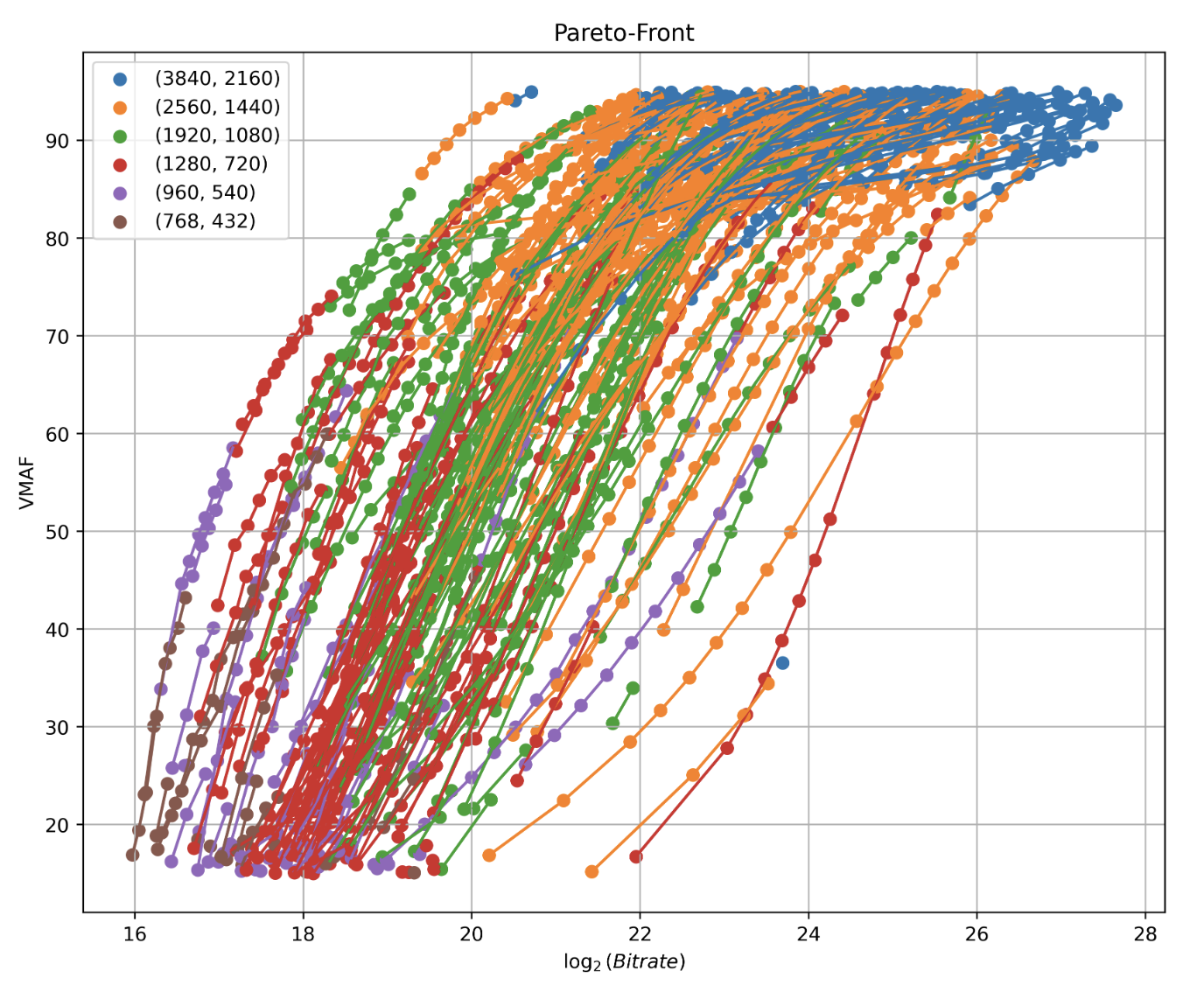
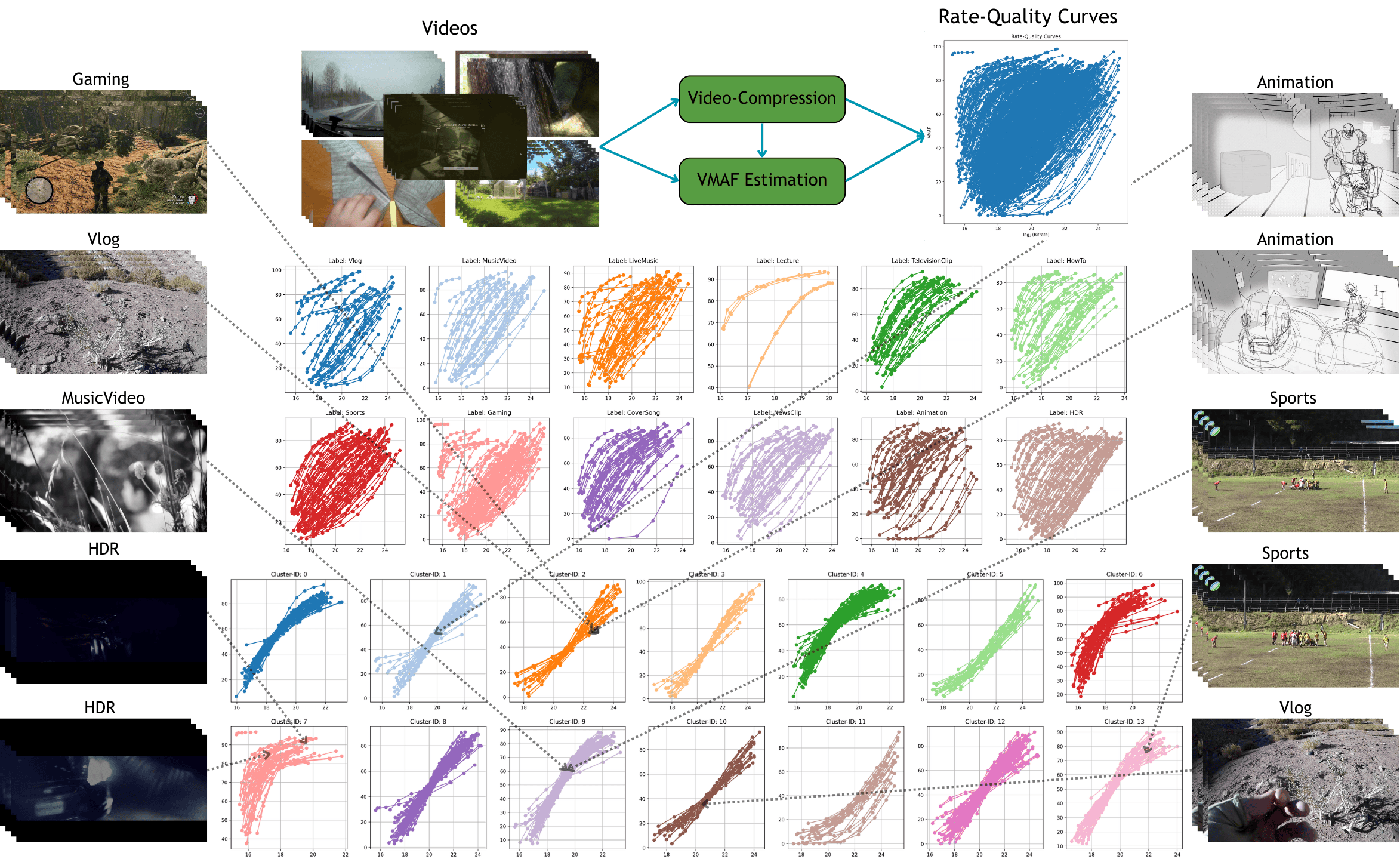
Constructing Per-Shot Bitrate Ladders using Visual Information Fidelity
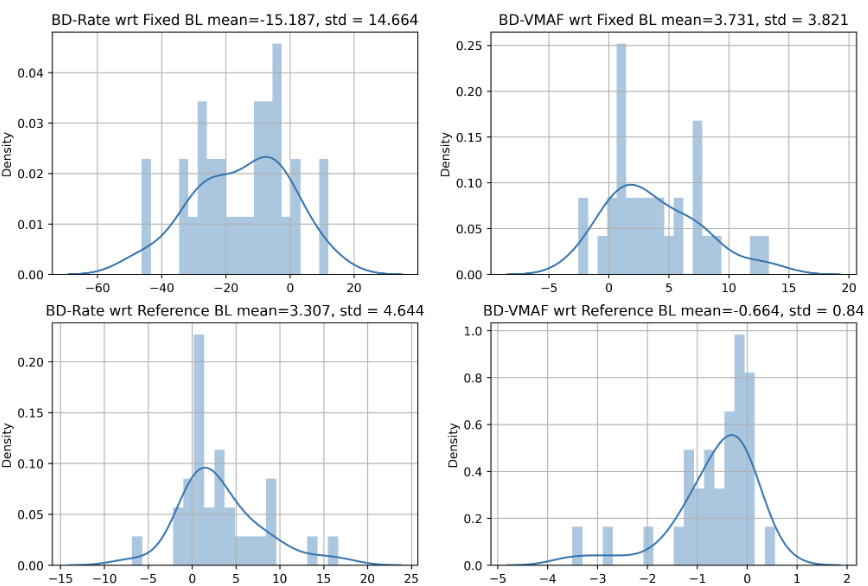
Bitrate Ladder Construction Using Visual Information Fidelity
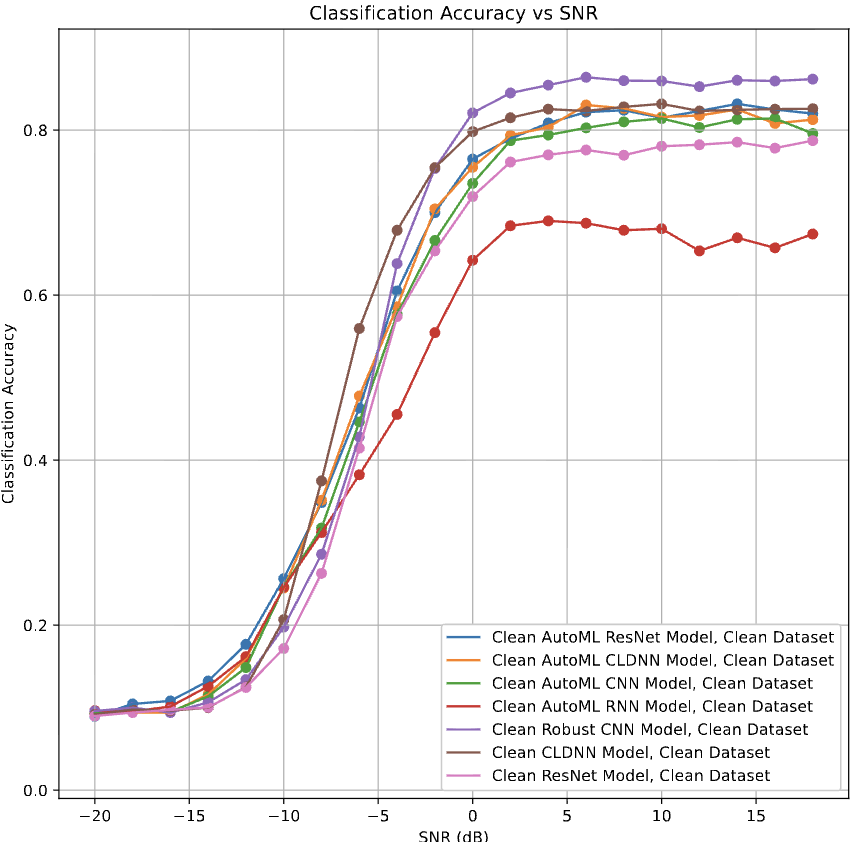
AutoML Models for Wireless Signals Classification and their effectiveness against Adversarial Attacks
Experience
-
MPI Research InternSamsung Research America
Built a generative framework for high-resolution 4K image synthesis, scaling state-of-the-art pretrained diffusion models to 4096×4096 with structural refinement methods that suppress synthesis artifacts and maximize perceptual quality and spatial consistency.
-
Wireless Systems InternSkydio
Optimized drone-to-controller video streaming using adaptive streaming protocols and Video Quality Assessment (VQA), curating an empirical dataset and designing multi-tier frame-rate switching driven by visual features and real-time drone telemetry.
-
Application Development InternOracle
Engineered an AI-powered conversational interface using Natural Language Understanding (NLU) for the Oracle Journeys application, integrating it with Oracle HCM Cloud via REST APIs and optimizing intent classification and entity recognition.
Projects
Time-Constrained Representation Alignment (TC-REPA)
Tested restricting Representation Alignment (REPA) loss to high-noise timesteps on SiT-XL/2 flow-matching models, establishing that the effective axis for relaxing alignment is the training iteration, not the diffusion timestep.
Diffusion Models
Representation Alignment
Flow Matching
Per-Prompt Evaluation of Guidance Strategies in T2I Models
Benchmarked seven CFG-family guidance strategies across SDXL, PixArt-Σ, SD3, and FLUX on T2I-CompBench++, revealing that aggregate FID/IS scores conceal compositional hallucinations exposed only by per-prompt distributional evaluation.
Text-to-Image
Classifier-Free Guidance
Compositional Evaluation
High-Resolution 4K Synthesis using Few-Step Models
Benchmarked diffusion, flow-matching, consistency, and flow-map-matching models for 4K image synthesis, quantifying the perceptual-quality and inference-efficiency trade-offs between knowledge-distilled and principled few-step techniques.
Few-Step Generation
High-Resolution Synthesis
Diffusion / Flow Matching